

The art of crafting solutions
The art of crafting solutions
A really cool example of how we can solve problems one step at a time

Hello, Hypers!
Last week we talked about some probability concepts that play a crucial role in Artificial Intelligence. This time I’m going to try something different. I’ll be talking about algorithms and problem-solving.
We’ll start with the apparently simple problem of finding prime numbers and will end up with a great solution from one of the greatest computer scientists ever. Then I’ll quickly talk about a data structure I came up with when I was an Undergrad student as another example of crafting solutions. Although this post will be a little bit large :), I think it’ll be worth it to read it till the end.
Of course, the goal of this post is not to teach you how to get prime numbers or how to create new data structures, but to walk you through a step-by-step analysis that leads us to a cool solution. I want to show you how to craft a good solution.
So, let’s get started!
Note: I’ll be using some Python-ish pseudocode for the examples. I assume that you have basic knowledge of programming and big-O notation.
Two algorithms, one problem
The problem is to find all prime numbers from 0 (zero) to N. The kind of problems you learn to do when you are beginning your journey in programming. I want to start with the simplest solution.
In the naive algorithm, we iterate over all numbers x from 2 to N. Then we check whether x has any divisor besides itself and one. For the last step, we can check for every number d between 2 and x - 1 whether it is a divisor or not.
There is room for improvement in the last step because we only need to check the divisors that are less than or equal to the square root of x. A pseudocode of the algorithm is written below:

What's the runtime complexity of the previous algorithm? Well, we take every number from 2 to N, and for each one, we iterate over all its possible divisors, so we make O(N*sqrt(N)) operations, where sqrt stands for the square root function.
What about memory? We only store the primes we find. For a big enough N, the amount of primes is relatively small compared with N. So, let's denote the memory complexity as O(Primes(N)), where Primes(N) is the number of primes between 0 and N. Note that this is optimum in terms of memory because we need at least to store all the prime numbers.
Probably you already know that there is a better algorithm to find all the prime numbers in a given range: The sieve of Eratosthenes. Let's look at it.
The idea is to maintain an array of length N where every entry is either false or true. If the i-th position in the array is true, then we say that i is a prime number, otherwise i is not prime.
We start with all positions with a true value and then, for every position, starting with i = 2 we make false every multiple of i. We end up with an array in which every position with a true value represents a prime number. The code with some optimizations is presented below:
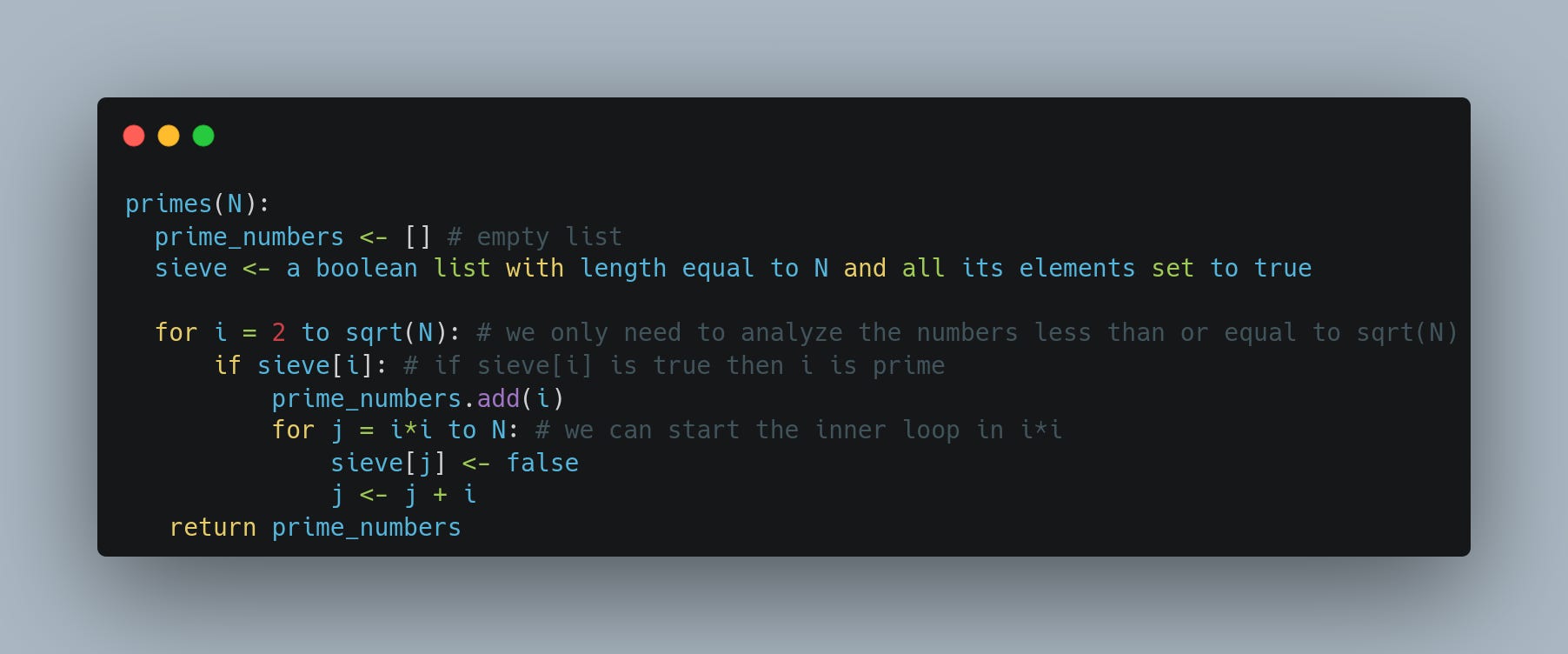
It can be proved that the algorithm described above does O(N log(N)) operations which is better than the naive approach. Even it can be improved to O(N). But we need to store an array with all the N numbers, and thus, we end up with a more expensive algorithm in memory terms. Here we have the trade-off: time in exchange for memory.
Can we design an algorithm that is faster than the naive idea but cheaper in memory terms than the sieve of Eratosthenes?
Dijkstra and the production line
In the '60s, E.W. Dijkstra wrote in one of his manuscripts [PDF] an algorithm that combines the naive and the sieve ideas. But before we talk about it, let's analyze the differences between the two previous algorithms.
When applying the naive algorithm we focus on analyzing whether every number is prime or not. When applying the sieve we analyze, for every prime number, all its multiples. The difference can be illustrated with the following analogy.
Imagine we want to build several products, like action figures. We have two options: building them one by one or applying a production line and in every stage, we add one component of the action figure. With the latter, we end up producing more in less time, but we need the "line infrastructure".
Dijkstra combined those ideas by analyzing a number at a time but taking advantage of the previous operations. We can maintain a pool of primes that have been already discovered, and, for each of those prime numbers store the least multiple that has not been analyzed yet. For example:
If we are analyzing number 6, then we have stored primes 2, 3, and 5, along with their least-not-analyzed multiples which are: 6 for 2, also 6 for 3, and 10 for 5.
Then, when analyzing a new number we take the smallest multiple stored until that moment, and if that multiple is greater than the new number, then we have found a new prime, otherwise, we have a composite number and we need to update the multiples of the stored primes that have the new number as its least multiple.
We begin storing the prime number 2 with the least multiple 4 as well. Then when analyzing 3 we find that 4 > 3 so 3 is prime. We store 3 along with its smallest multiple that has not been analyzed yet (6). When analyzing 4 we find that 4 is stored as a multiple of 2, then we update the multiple of 2 that now will be 6. When analyzing 5 we find that 6 > 5 so 5 is a prime number and we store it along with 10, and so on... The code is presented below:

The previous method only stores the prime numbers and another number for each of those primes. So we have a memory complexity of O(Primes(N)) which is the same as the naive idea. If we store the prime numbers along with their multiples in a structure like a heap, we get a time complexity of O(N*log N) which is the same as the sieve! So we got what we wanted!
The trick here is that we don't need to mark every multiple of the given prime but just the least multiple.
I need to say that this is not a practical idea in the sense that the memory complexity of the sieve of Eratosthenes is not that bad and it is an algorithm very easy to implement. My point is that sometimes you have several ideas, and each of them cannot be applied because of some flaw, then maybe is a good idea to combine their strengths and you can get a hybrid applicable solution for your problem. The Factory of Primes of Dijkstra has taught me to think in that way, although I have never implemented that algorithm in real-life scenarios.
Combining arrays with linked lists
Arrays are simple structures that allow us to get an element by its index in constant time. But we need O(N) operations to insert or remove an element to/from the array in the worst case, where N is the length of the array.
On the other hand, linked lists are structures composed of nodes. Every node has a reference to the next one, and, in the case of doubly-linked lists, each node has also a reference to the previous one. In this case, we need O(N) operations to reach a node in the worst case, but the insert and remove operations can be done in constant time. I think it's natural to think about a "perfect data structure" that allows us to make the three operations in constant time. Sadly, such a structure does not exist, but I have found a middle point between the two opposite poles.
The "issue" with arrays is that they maintain a reference to all of their elements. That allows us to retrieve any element with the same amount of operations no matter where the element is. But maintaining those references is what makes the insertions and deletions so costly. When it comes to linked lists we only maintain a reference to the first and the last node and each node has a reference to its neighbors. So, when inserting or removing a new element we only need to change a few references. But that lack of references is the cause that we have to spend so many operations to get an element in the worst case.
Viewing the problem from that angle, the idea of finding a middle point in the number of references seems natural. What happens if we maintain a reference to sqrt(N) nodes of the linked list instead of referencing just the first and the last element?
That allows us to have a list of length sqrt(N) such that the distance between each of those nodes in the actual list is sqrt(N). Having that, we can do each operation (index, insertion, and deletion) in O(sqrt(N)).
I have written a post about this data structure. You can read it here
Conclusions
We have seen two examples of combining existing solutions to get another one that has some of the good qualities of each of the previous ones. My purpose was to show you this way of thinking, not just specific examples.
Note that in the case of Dijkstra's idea, we could achieve the time of the fastest solution and the memory complexity of the naive algorithm. In the second example, we just got a middle point, so the fastest solution is still faster and the memory-cheaper solution is still cheaper, but the new structure is like a decathlon athlete, it is good in every specificity, but not the best in anyone. So don't try to find the silver bullet, remember the no-free lunch. Even Dijkstra's idea has the disadvantage of being harder to implement and understand.
Hope you have learned or found attractive this post. Feel free to ask whatever you want or give me some feedback, I will appreciate that a lot. Stay tuned for the next post and remember to always try to see what’s going on under the hype.
See you!
O(sqrt N) algorithms are fascinating. I have some examples I want to show also, where we can take advantage of the structure of the problem and come up with a solution that might be not as efficient as O(logN) but will be more efficient than O(N).
That middle point often requires some cleverness and a good understanding of the problems. I think it's good that you wrote about this. It can be a game-changer for someone trying to craft some good old ad-hoc solutions.
Thanks for sharing!