
The Challenge of Randomness
Using Math and Computation to identify something that is invisible to us.

Hello, Hypers!
The AI hype is here to stay and today I wanted to write about some basic principles that make it happen. One of the pillars that supports AI advancements is Probability Theory and Statistics.
These are quite old branches of Math. We have witnessed a lot of applications and great results in these fields over centuries. But those previous achievements seem like nothing compared to our achievements in the last decades. What makes the difference? There are many differences, but one of the most important (and sometimes overlooked) is the ability to implement probabilistic algorithms.
Here, I’m not defining what an algorithm is. You can refer to Alejandro Piad Morffis for that. However, the definitions of algorithms seem to imply an inherent determinism. In other words, if I feed an algorithm with the same input repeatedly, I should get the same output every time.
On the other hand, a probabilistic algorithm could produce different outputs each time. Each possible output has a probability of occurring. This way, we don’t have a deterministic behavior anymore, just a probabilistic one.
But if computers are so deterministic, how can we implement probabilistic algorithms? And how do we test if this probabilistic behavior is correct? We have two big questions so we need two articles to answer them. In this one, we’ll be learning very basic intuitions and algorithms to create randomness. Next week, we’ll be learning how to test and improve our probabilistic algorithms.
So, let’s get started!
Random… I mean, Uniform!
The first thing I want to do is to separate two important concepts in Probability Theory: Randomness and Uniformity. We tend to use them interchangeably but they are not the same thing. Randomness only refers to some degree of uncertainty. Let’s use three examples: measuring the height of people, calculating the time until the next phone call arrives, and flipping a coin.
If we measure the height of the people from a specific region and draw a histogram, we’ll see a pattern. We’ll find a lot of people of medium height while there will be fewer too short or too tall people. Our histogram would look like this.
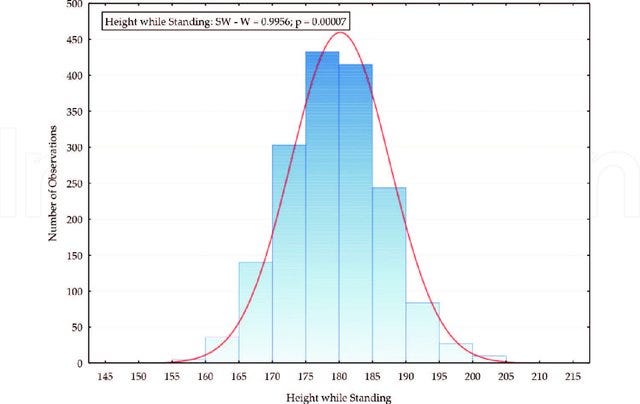
Taken from Bed Size, Quality Sleep and Occupational Safety: An Investigation of Students at Slovak Universities. Under CC BY 3.0 Licence
The probability of getting a medium height is larger than the probability of getting an extreme value for the height.
In the next example, we want to calculate the time until the next phone call arrives. Of course, this calculation depends on other things like our occupation, our habits, our relationships, the time of the day, etc. But let’s ignore those factors. After all, this is just an educational example. In this ideal scenario, we should observe something like this:
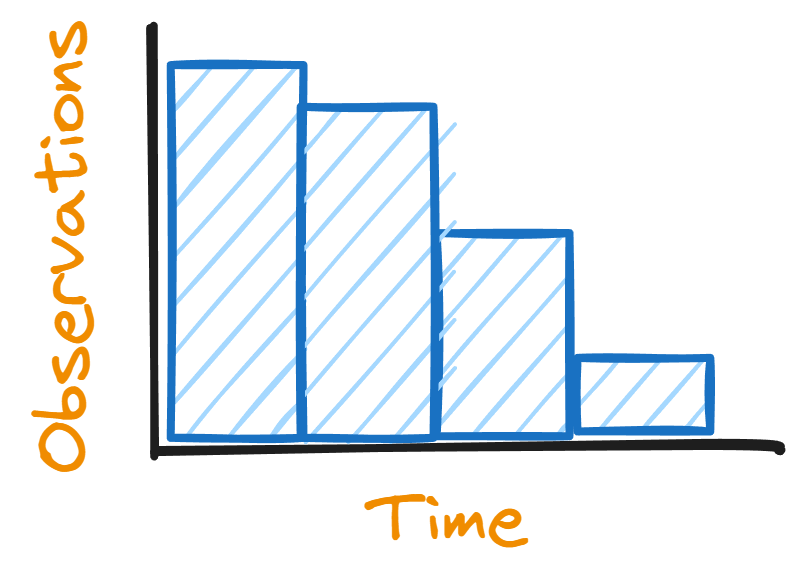
The intuition here is that the longer the time interval T is, the more likely is that the call arrives before the end of T. That’s why the probability seems to decrease while the time interval length increases.
The previous are examples of random processes, but note that the possible outcomes had different probabilities. And that’s why these are not uniform processes. In a uniform random process, each outcome should have the same probability. For example, when flipping a coin the probability of getting a head is the same as the probability of getting a tail (assuming a fair coin).
When we say, name a random color, we usually mean pick a color randomly and uniformly. We expect each color to have the same probability of being named.
Let’s Generate a Uniform Random Number!
Uniform random numbers are very useful because if we are able to generate them, then we can generate any other random number. So, the possibility of creating probabilistic algorithms relies almost exclusively on the possibility of generating Uniform Random numbers. That’s why we can say that generating uniform random numbers is the most important probabilistic algorithm in the world.
Despite this motivation, it is not clear yet how to create randomness from within a deterministic system like classical computers. So, let’s review the possibilities:
In the last decade, we have seen big improvements in Quantum Computing. Every year, we get cheaper and more powerful quantum processors. This seems like a way different topic but Quantum Computing could be the key to achieving a more reliable and efficient way to get random numbers.
The main idea here is that the most basic building blocks of our Universe have a probabilistic behavior. So, just following this behavior gives us a great way to generate randomness. Actually, quantum algorithms are all probabilistic algorithms. If classical computers are deterministic systems, quantum computers are probabilistic systems. I won’t get too deep into this topic. If you are interested you can check the first season of my series on Quantum Computing here.
But we don’t have to look to the most tiny particles in our Universe to observe random processes. There are many examples of random processes in the macroscopic world. For example, atmospheric noise and thermal noise are two phenomena with proven probabilistic behavior. Again, if we use measures of this kind of process as inputs to our “uniform random numbers” generator, then we could generate randomness.
However, all the previous possibilities are very costly and slow. Also, we are kind of cheating since we are not generating randomness from within a classical computer but we are taking randomness from an external source. It’s time to get serious!
The Pseudo Random Numbers
OK, we are going to cheat again. But at least now we’ll only use the resources inside our personal computer. The trick is that we are not going to generate truly random numbers but what are called pseudo-random numbers.
When we say we want to generate a uniform random number, we mean that we want our output to be a number between 0 and 1. Of course, we want all the numbers between 0 and 1 to have the same probability of being generated.
Suppose we have two integer numbers a and M. If we want to generate the next uniform number, then we can use the following formula:
That means that if we are going to produce the next uniform random number, we take the previous number we generated and multiply it by a. Then we take the remainder of this product when divided by a fixed big number M. If the result of this calculation is divided by M, then we’ll get a number between 0 and 1.
Maybe some Python code makes it clearer:
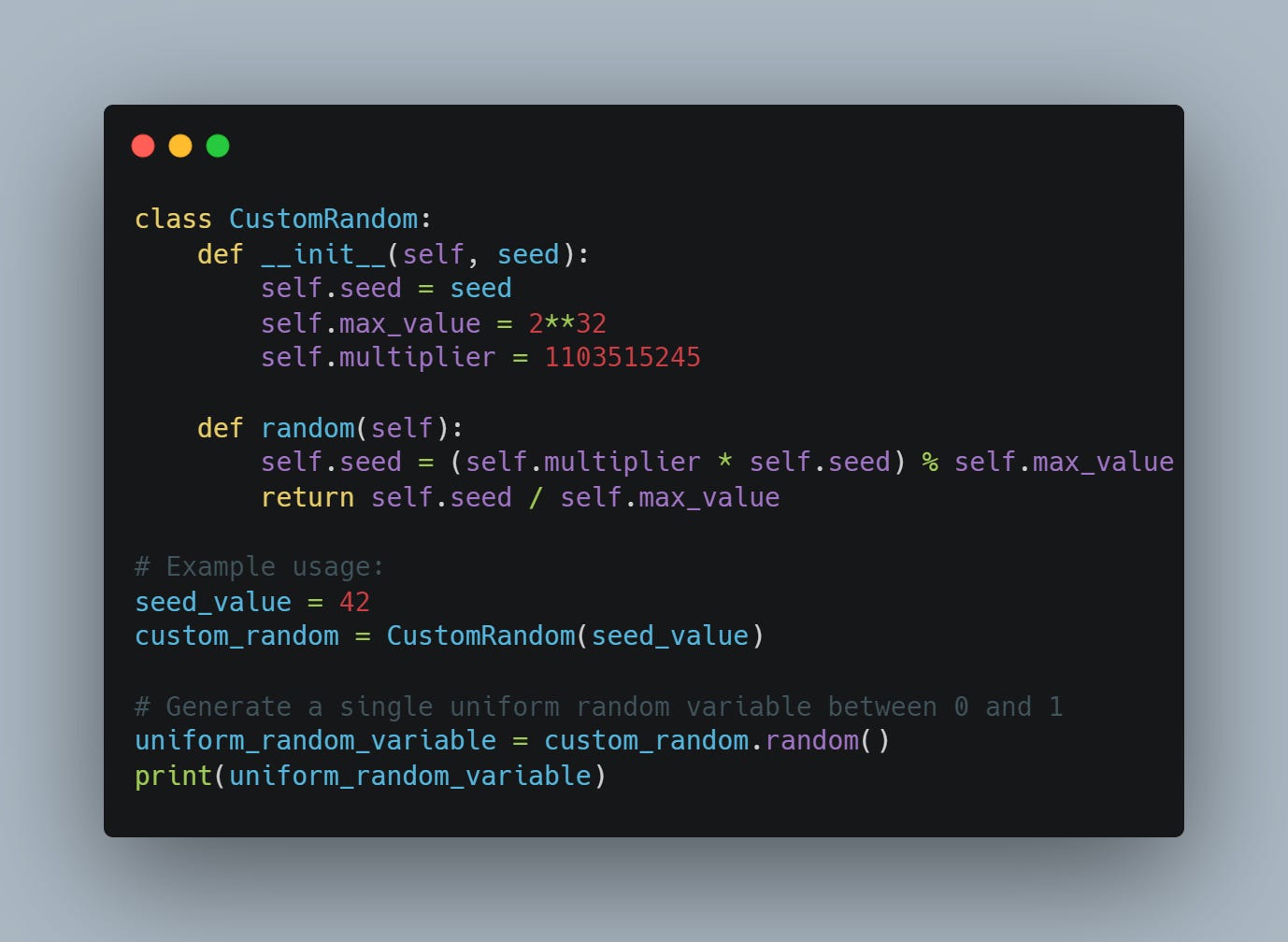
This code answers a question you may be asking. How to generate the first uniform number? As you can see, we need to define a seed. This is our first random number. That’s why these are called pseudo-random because they depend on a seed selection. If we pick the same seed, we’ll get the same sequence of “uniform“ numbers. We might take, for example, the ticks of the PC clock as a seed. But that won’t change the fact that these are not truly random numbers.
On the other hand, this is a very fast, cheap, and easy-to-implement method to get random numbers. It would be great if this pseudo-random generator was a good approximation to a truly random generator. But, how do we measure how good this pseudo-random generator is? And how can we improve it?
These are questions to be answered next week. So make sure to subscribe and stay tuned! Thank you so much for reading.
See you soon!