

Improving linked lists
Improving linked lists
Solving a hard problem is one of the best feelings in the world. This week, I'm sharing one Data Structure I created myself some time ago and I'm really proud of.

Hello, Hypers!
If you allow me, this week I’m getting a little bit cocky :)
I’m going to talk about a data structure a came up with some time ago to solve a problem I had with my CS Degree Thesis. Here we go!
You know the situation is tricky when you need more than just arrays and dictionaries. That was my case at that time. I needed an indexed data structure that supported insertion and removal operations as fast as possible.
With an array, I can get the i-th element very fast (this will be called the index operation. I provide an index i and get the i-th element of the list), no matter what the value of i is. But when it comes to inserting or removing an element from the middle of the array things change a little bit.
On the other hand, linked lists offer a slower index operation. We need to traverse a long segment of the list to get the element we are looking for. But we can make faster insertions and deletions.
In this article, I will write about a solution I came up with. This is a new data structure that somehow combines arrays and linked lists to get a middle point that suited my requirements. I don't know whether this is a truly novel data structure. Furthermore, I don't think it is an awesome idea. I just used some clever and relatively popular techniques to achieve my goal.
The next section is about the differences between arrays and linked lists, their respective strengths, and their weaknesses. If you are just interested in the data structure specifics, you can skip it. Then I'll talk about the core idea, and later, I'll give some implementation details.
Note: I assume you have some basic knowledge of algorithmic complexity and big-O notation.
Arrays vs. Linked Lists
Arrays are contiguous memory slots to store sequences of data. We arrange some elements in such a way that we keep a reference to every single one of them. For example, if we have an array that contains numbers from 1 to 10, we have a reference to every memory slot that contains each of those ten numbers. That allows us to get any element by the index it has in the array really fast.

We have an implicit mapping from index to element. No matter the value of the index, the operation will always be equally fast. That means that doing array[0] is as fast as doing array[9] because we keep all the references at the same time. That's the most useful feature of arrays, we have access to any position in constant time, no matter the size of the array, or the position itself.
This great feature is also the reason we can't insert or delete elements with the same ease. We need to keep elements in contiguous positions and maintain the references to them. When deleting an element, we are creating holes in the middle of the array, and that is not allowed. So we need to fix the references manually and fill the holes. The same happens with insertions, in this case, we need to create the hole first and then, fill it with the new element.
Thus, to insert/delete an element, we need to rearrange the array. If we have an array with N elements, we'll need to rearrange O(N) of those elements when doing an insertion/deletion. I needed to do it faster!
Linked lists don't maintain all those references in the same way. They are composed of nodes that store an element but also the reference to the next node. This way, we only maintain a direct reference to the first node of the list (called the head), this node has a reference to the second one, the second one has a reference to the third one, and so on. In the case of doubly-linked lists, every node has a reference to both the next and the previous node, and we also keep a direct reference to the tail of the list (the last node).
Thus, looking for an element in a certain position implies traversing O(N) nodes in the worst case. The good thing is that we can insert or delete an element without worrying about the holes because we only need to change a few references. But I needed to have access to positions in the lists in a faster way!
I needed to make faster insertion/deletion (better than O(N)), but yet be able to retrieve the i-th element of the list in less than O(N) operations as well. Is important to note that when I say insertion I mean an operation that receives an element and a position, and then inserts the element in that position. The delete operation is defined in the same way.
In the next section, I'll introduce a data structure that lets us fulfill such requirements.
An Indexed Linked List
As we saw in the previous section, the "problem" with arrays is that having all those references make the insertion/deletion slow. But the few references of linked lists are a problem as well, because we need to make a lot of operations to get the element at a given position. Thus, it seems reasonable to think about finding a middle point in the number of references.
First of all, I need to say that no data structure lets us make all the index, insert, and delete operations in constant time. So, a "perfect world" is out of the discussion. Let's move on.
I was thinking about having a doubly-linked list with more direct references. Instead of just keeping a reference to the first and the last node, I will keep also references to inner nodes, but how many references would I need? If I maintained just a few of them, the index operation might be slow, but if I maintained too many references, then insertions and deletions would take more time.
After thinking for a while, I came up with the right number of references: sqrt(N) (here sqrt stands for the square root operation). The idea is to keep a list of references, the length of that list will be sqrt(N). The other important property is that every referenced node will be at a distance of sqrt(N) from the next node in the reference list.
For example, suppose we have a doubly-linked list with the numbers 1, 2, 3, 4, 5. Then our reference list will contain two references because of 2 < sqrt(5) < 3. Also, every node referenced in the list will be at a distance of sqrt(5) of the other node referenced in the list. So a possible list will be one that contains the second and the fourth node. Another possibility would be a list with the third and the fifth nodes. In both cases, the distance between nodes is less than sqrt(5).
Note: When I say
sqrt(N)I mean the largest integernsuch thatn <= sqrt(N)
By keeping such a reference list we can make all the index, insert, and delete operations in O(sqrt(N)). Note that we got a slower index operation to achieve a faster insertion/deletion.
Note: By the way, I borrowed some ideas from a technique called sqrt decomposition. You can check it out here.
Now I'm going to explain the insert, delete, and index operations.
Inserting an element
As I said, I maintain a list of selected nodes. The length of this list is always sqrt(N) and the distance between two consecutive selected nodes in the actual list will be also sqrt(N).
Note: The example code is written in Python. The original code was written in Lisp. If you want to check the original implementation along with a detailed explanation check this notebook. If you want to know why I like Lisp so much, check out the posts of the last two weeks.
Every time we insert a new node in the list we need to check whether the new length of the list has a new integer sqrt(N). In that case, we need to update the selected nodes list. It would be like:
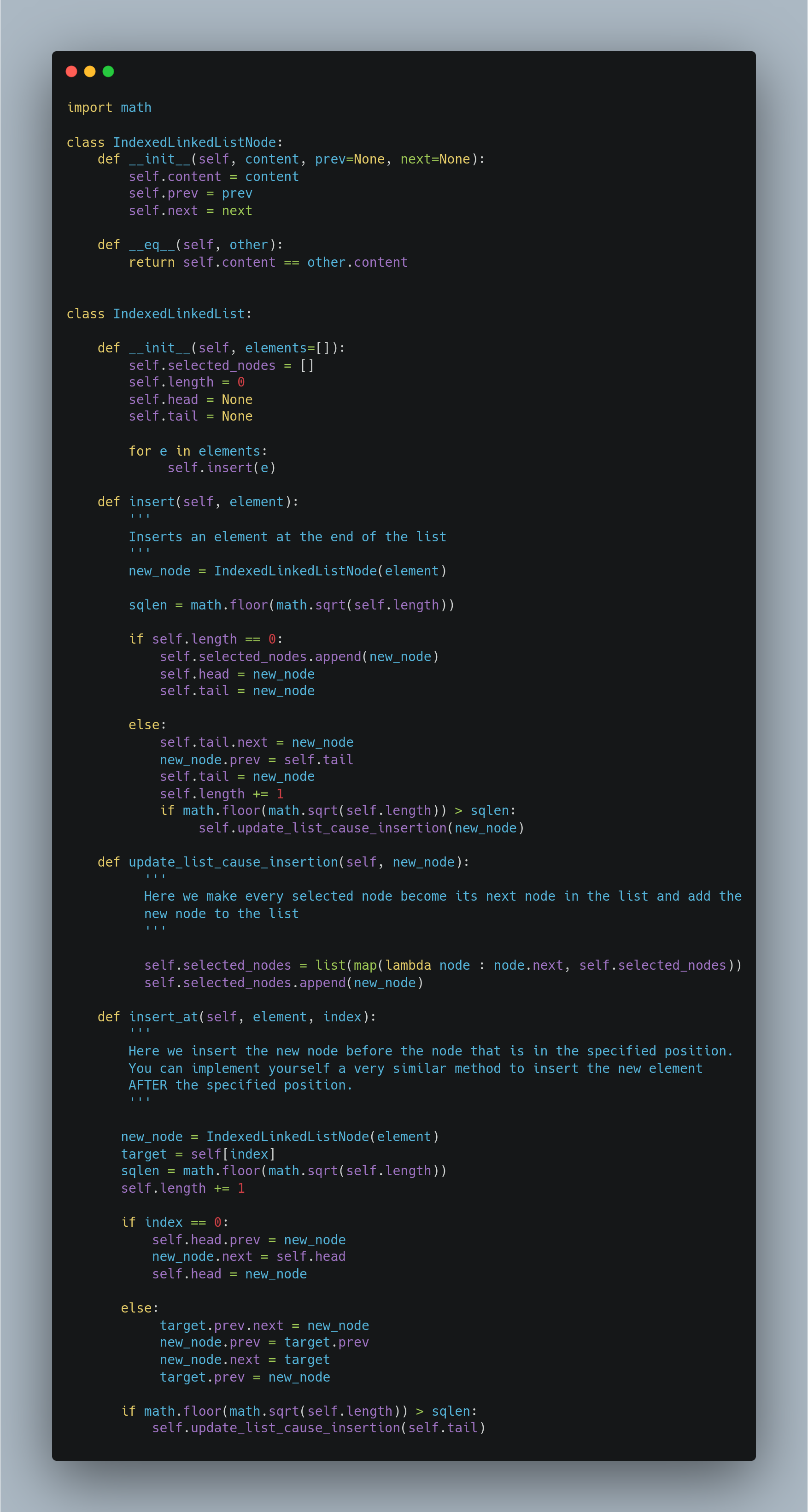
It can be proved that we always obtain a selected nodes list of length sqrt(N) and with at most sqrt(N) distance between any pair of consecutive nodes. I'm going to skip the demonstration to keep the article as simple as possible. As you saw, we used self[index], that’s because we implemented the index operation with a magical method. I’ll show you how I did it soon, but let’s first implement the delete operation.
Deletion
This is a very similar method. Is like doing the inverse operation. We just need to take care of some corner cases like deleting the only node in the list and deleting the first or the last node.
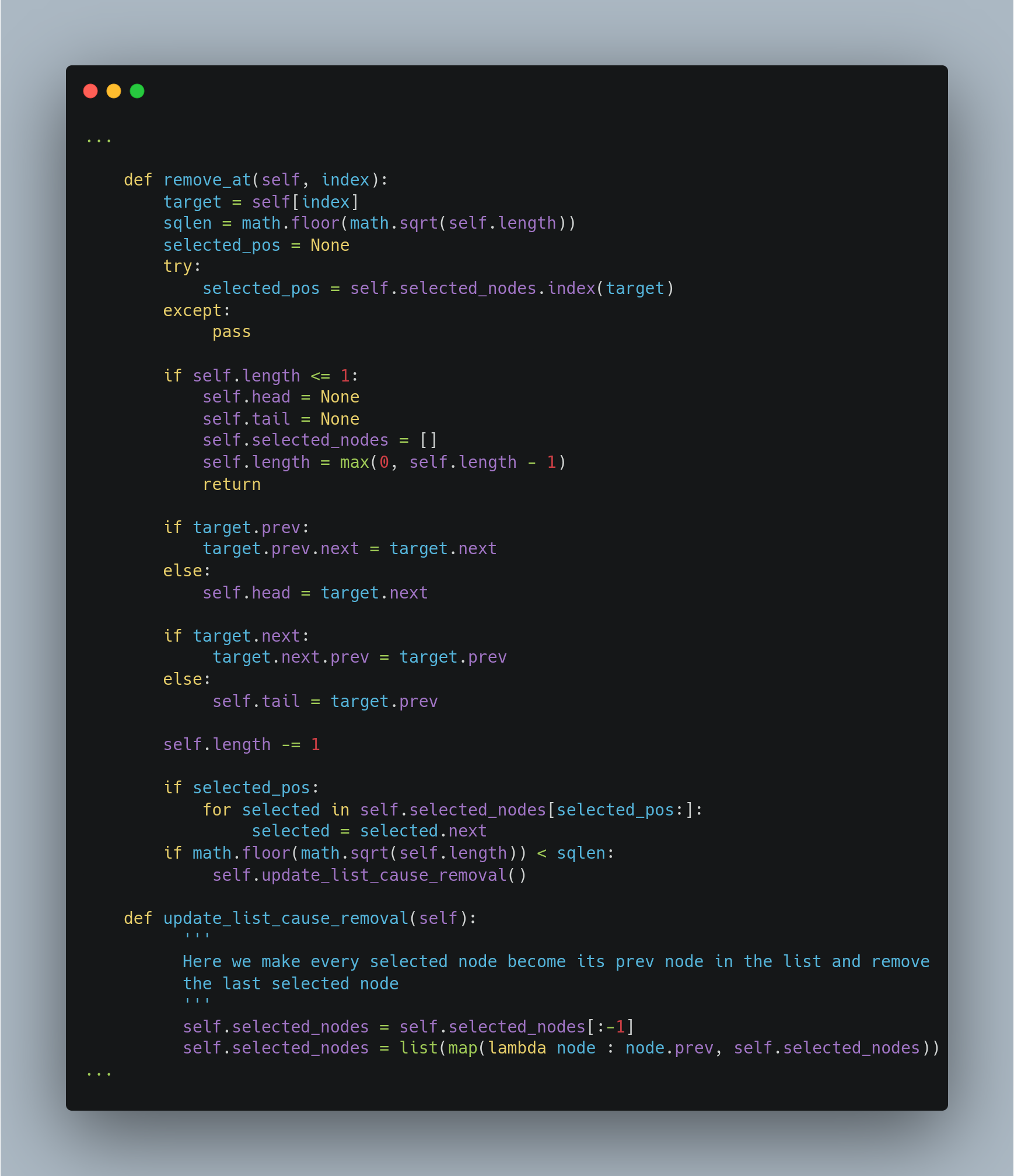
Until here we have achieved the requirements for insertion and deletion methods. But that is assuming that the index operation (self[index]) could be done also in the required time.
Index
Let's see how to implement the index operation. This is the last piece of the puzzle. It is a trickier method that would require more explanation to understand the insights. As I said, I would like to keep this article as simple as possible so I'm not going to explain too many details about this operation.

That's it. We have completed our Indexed Linked List implementation!
Conclusions
In this post, we defined a new data structure that allows us to do insertions, deletions, and indexing in O(sqrt(N)) where N is the length of the list.
I didn't want to go into the implementation details and proofs of correctness and time complexities because I wanted the article to be accessible to a wider audience (sorry for all the code but I think many of you will enjoy that as well). I know some parts of the code can be obscure but I consider that talking about a problem and sharing ideas to solve it is very helpful for everybody.
This is a good example of what we talked about some weeks ago in the following post:

If you want me to make a more detailed article with all the formulas and demonstrations just let me know. You can react to this article and leave a comment, or you can follow me or @-me on Twitter to talk about this or any other CS-related topic. Make sure to subscribe!
Also, if you liked this and/or any article in this newsletter, I would really appreciate it if you share it with your friends and colleagues.
Stay tuned!